Titian were already using Terraform to deploy AWS infrastructure for their clients, however during initial discussions and a period of discovery we were able to identify some efficiency and workflow improvements that would allow the Titian team to focus on the future development of their applications. The solution consisted of an improved development pipeline and the migration of Titian clients to adopt this.
THE SOLUTION
This solution needed two separate elements:-
Development of the new pipeline controlled deployment process
Migration of existing Titian clients environments to utilise this new pipeline deployment process (including eliminating any drift in the Terraform state files)
The pipeline would need to ensure that future environments are managed effectively, but also be sympathetic to the existing environments and how they would need to be migrated and subsequently managed under the same deployment pipeline.
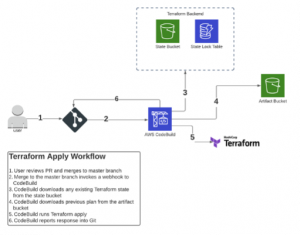
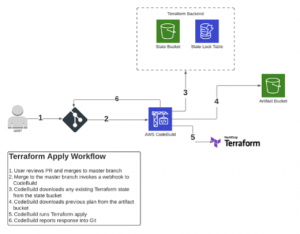
The first step of enabling full management of the environment via Terraform was to update the state configuration to use S3 bucket and DynamoDB. Within the S3 bucket Terraform state files are created for each client, this scopes the blast radius of any individual deployment to a single client and minimises the impact should any problems occur inside or outside of the Terraform state.
Secondly, in order to track the intended configuration for each client and have a trigger point for pipeline runs, Terraform configurations files for each client are also maintained in Git. This was configured using a separate repository purely for client Terraform configurations, with a different repository containing the generic, reusable modules.
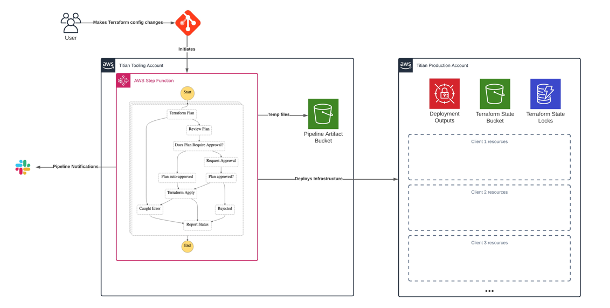
The above two workflows were then incorporated into AWS Step Functions to drive the full Terraform deployment process, with the pipeline residing in a Tooling AWS Account. The pipeline was then configured to deploy resources to the main Production Account.
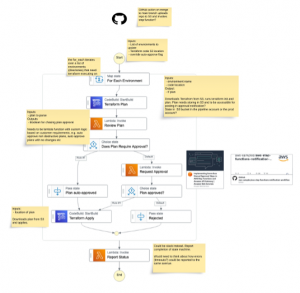
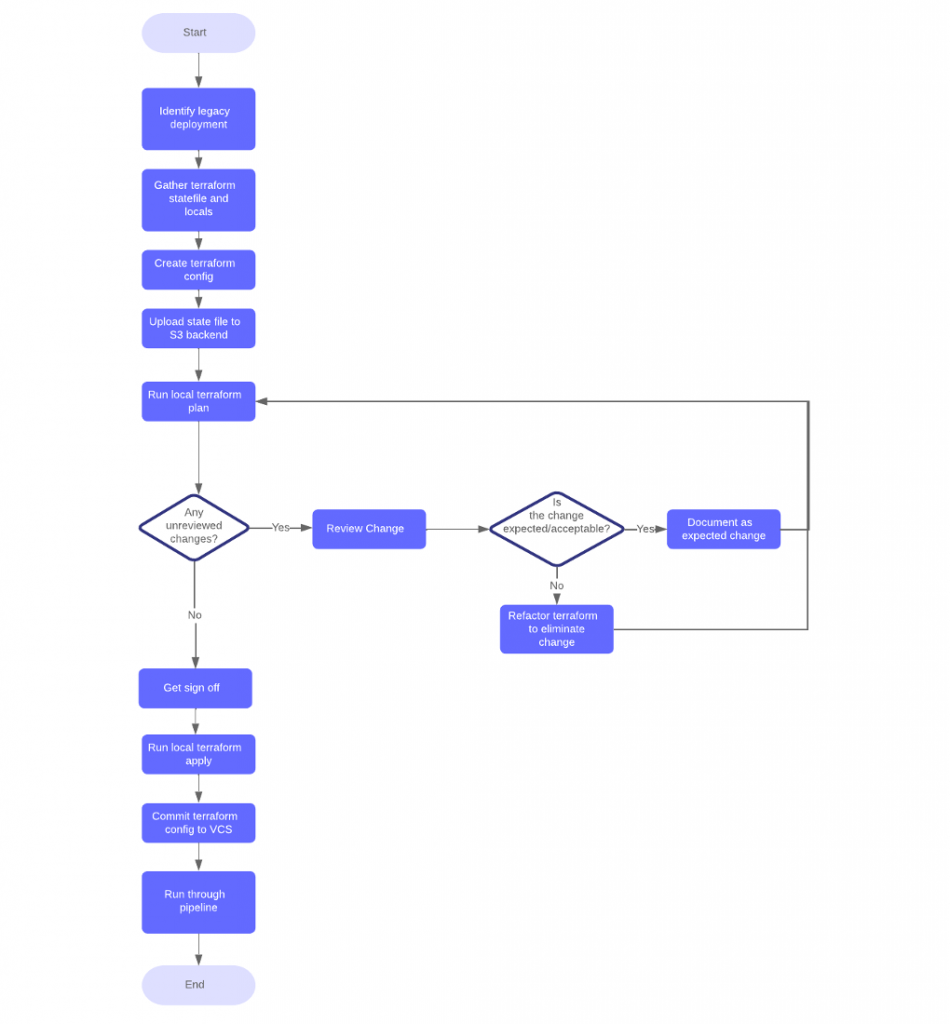
This flowchart details the activities discovered during the initial investigation, and subsequently ratified into the High Level workflow for the migration of each legacy client deployment to the pipeline.
The Terraform testing/refactoring was performed locally for speed of development, then committed to the version control system after customer approval. Once committed it was then automatically and carried through the pipeline to complete the migration. Future environment changes would be handled via changes committed to the Terraform repository which would launch the pipeline.
As a prerequisite for this process it is required to have the tf state file and local variables used for the initial deployment. The local variables are combined with a generic set of Terraform config files to become the basis of the new deployment. The state file is stored in S3 where it is accessible from the pipeline.